Projemizin bu bölümünde, GeneCards kullanarak eriştiğimiz bilgiler üzerinden gitmeye devam ederek CFTR genine ilişkin genomik ve proteomik verilerle meşgul olacağız.
Önceki yazıda belirttiğim gibi, GeneCards, bilinen genler hakkında varolan ve güvenilir olduğu düşünülen bilgileri tek bir çatı altında toplama gayreti sonucunda ortaya çıkmıştı. Böylece, birçok veritabanından farklı gayretlerle elde edebileceğimiz verilere tek bir seferde ulaşabiliyoruz.
İlgilendiğimiz gene ilişkin genomik konum [lokasyon] bilgisine Genomic Views başlığı altında ulaşabiliriz. Bu bölümdeki en faydalı bilgi, genin kaç baz uzunluğunda olduğu. Diğer kritik bilgi ise, bu gene ilişkin alternatif bir konumun olup olmadığı. CFTR geni için başka bir bölge de rapor edilmiş, bunun birkaç sebebi olabilir.
Genomik veritabanları hakkında bilmemiz gereken en önemli şey, bu veritabanlarının sürekli değişken olduğu ve birden fazla kaynak tarafından üretildiğidir. İnsan Genom Projesi'nin ilk taslağının açıklandığı sıralarda DNA dizilimleme çalışmaları, iki farklı bireyin DNA'sı üzerinden devam ediyordu (biri James Watson). Bildiğimiz üzere insan genomu birçok delesyon [deletion] ile şekillenmiştir, bu durum da karşımıza, aynı gen için farklı genomik konumlar olarak ortaya çıkabilir. Genomik konum bilgisi bir referans noktasından itibaren hesaplanır, ancak aralardaki muhtemel delesyonların [deletion] veya deneysel hataların etkisi bu referans noktasından uzaklaştıkça artar ve karşımıza farklı genomik konum bilgileri çıkar. Buradan çıkarılması gereken en önemli ders şudur: herhangi bir çalışma yaparken, hangi veritabanındaki bilgileri kullandığımız, üzerinde çalıştığımız veritabanına ne zaman ulaştığımız ve bu veritabanındaki bilgilerin en son ne zaman güncellendiği hayati önem taşır ve bunların bir çalışmada mutlaka kayıt altında tutulması gereklidir.
Bu bölümde gerçekleştireceğiniz ilk çalışma, mevcut genomik bilgilerin elde edildiği veritabanının versiyon numarasını bulmak olacak. GeneCards'ın ham verilere farklı veritabanlarından ulaştığını unutmayalım (İpucu: genlere ilişkin konum bilgisi, GeneCards'ın GeneLoc bölümünde yer alıyor, aradığınız şey buralarda bir yerde).
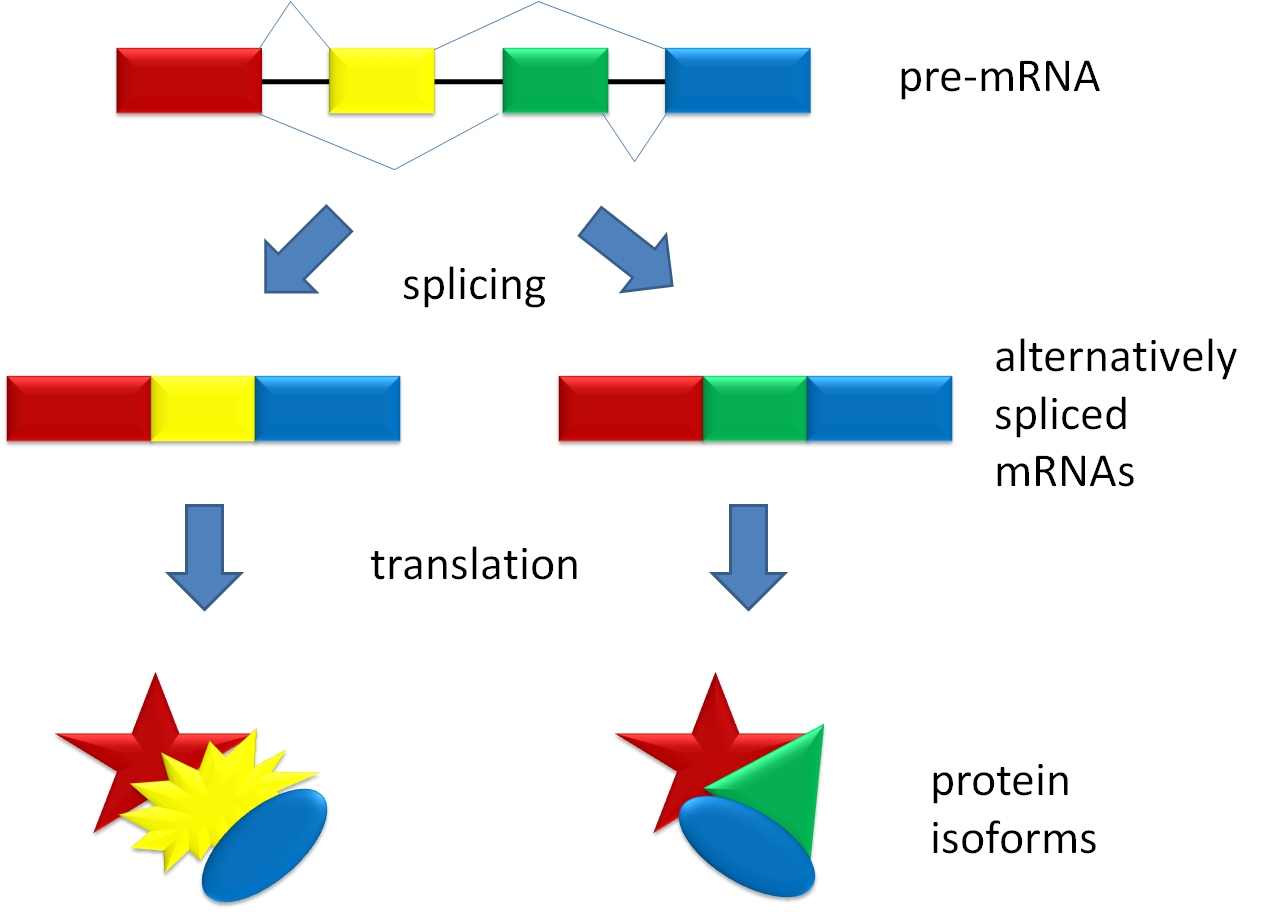 GeneCards'taki bir sonraki başlık, Proteins. Proteinlerle ilgili aklımızda tutmamız gereken ilk şey, DNA dizilimindeki bilgilerin birebir karşılığı olmadığı. Ökaryotlarda genler ekzonlar şeklinde organize olmuştur ve her bir ekzonun arasında fonksiyonunu tam olarak anlayamadığımız ancak protein bilgisi kodlamayan intron adı verilen bölümler yer alır. Yani, GeneCards'tan elde ettiğimiz DNA diziliminin büyük kısmı protein bilgisi kodlamayan bazlardan oluşur. Bir diğer etkense, alternatif kırpılma [alternative splicing] olayıdır. Alternatif kırpılma, hücredeki şartlara göre bir geni oluşturan ekzonların tamamının değil de, her seferinde sadece belirli bir fonksiyonel kısmının proteine dönüşmesi durumudur. Yani, elinizdeki DNA dizilimine bakarak hücrede tam da bu dizilime uygun bir proteinle karşılaşamayabilirsiniz. Proteinlere ilişkin bahsedilmesi gereken son durum ise, proteinlerin 3 boyutlu dünyada var olduklarıdır. Çeşitli tarihsel nedenlerden ötürü DNA dizilimlerine uzun ve ince bir veriymiş gibi davranmayı severiz: böyle bir basitleştirme bazı kavramlara daha kolay hakim olmamızı sağlar. Ancak atladığımız nokta, gerçekte DNA'nın hücre içerisinde 3 boyutlu olarak yer aldığıdır. 3 boyutlu konum ve şekil bilgisi DNA'nın hangi bölgelerinin etkin olacağı başta olmak üzere birçok özelliğini etkiler, yine de mevcut bilimsel yaklaşımda bunların birçoğunu gözardı ederiz ve bu durum görünüş itibariyle bize çok da fazla bir zarar vermez (gerçekte, belki de açıklayamadığımız birçok mekanizmayı anlamamıza engel oluyor olabilir). Ancak konu protein olduğunda durum tamamen farklıdır: aminoasit dizilimi bilgisi göreceli olarak çok daha az faydalıdır ve bir proteine ilişkin söz söyleyebilmek için o proteinin (veya alternatif kırpılma sonucu ortaya çıkan başka bir şeklinin [variant]) 3 boyutlu yapısına ait bilgiye kesinlikle ihtiyacımız vardır.
GeneCards'taki bir sonraki başlık, Proteins. Proteinlerle ilgili aklımızda tutmamız gereken ilk şey, DNA dizilimindeki bilgilerin birebir karşılığı olmadığı. Ökaryotlarda genler ekzonlar şeklinde organize olmuştur ve her bir ekzonun arasında fonksiyonunu tam olarak anlayamadığımız ancak protein bilgisi kodlamayan intron adı verilen bölümler yer alır. Yani, GeneCards'tan elde ettiğimiz DNA diziliminin büyük kısmı protein bilgisi kodlamayan bazlardan oluşur. Bir diğer etkense, alternatif kırpılma [alternative splicing] olayıdır. Alternatif kırpılma, hücredeki şartlara göre bir geni oluşturan ekzonların tamamının değil de, her seferinde sadece belirli bir fonksiyonel kısmının proteine dönüşmesi durumudur. Yani, elinizdeki DNA dizilimine bakarak hücrede tam da bu dizilime uygun bir proteinle karşılaşamayabilirsiniz. Proteinlere ilişkin bahsedilmesi gereken son durum ise, proteinlerin 3 boyutlu dünyada var olduklarıdır. Çeşitli tarihsel nedenlerden ötürü DNA dizilimlerine uzun ve ince bir veriymiş gibi davranmayı severiz: böyle bir basitleştirme bazı kavramlara daha kolay hakim olmamızı sağlar. Ancak atladığımız nokta, gerçekte DNA'nın hücre içerisinde 3 boyutlu olarak yer aldığıdır. 3 boyutlu konum ve şekil bilgisi DNA'nın hangi bölgelerinin etkin olacağı başta olmak üzere birçok özelliğini etkiler, yine de mevcut bilimsel yaklaşımda bunların birçoğunu gözardı ederiz ve bu durum görünüş itibariyle bize çok da fazla bir zarar vermez (gerçekte, belki de açıklayamadığımız birçok mekanizmayı anlamamıza engel oluyor olabilir). Ancak konu protein olduğunda durum tamamen farklıdır: aminoasit dizilimi bilgisi göreceli olarak çok daha az faydalıdır ve bir proteine ilişkin söz söyleyebilmek için o proteinin (veya alternatif kırpılma sonucu ortaya çıkan başka bir şeklinin [variant]) 3 boyutlu yapısına ait bilgiye kesinlikle ihtiyacımız vardır.
Bu bölümde gerçekleştireceğiniz ikinci çalışma tam da burada karşımıza çıkıyor. CFTR geninin kodladığı protein kaç aminoasit uzunluğunda, ve moleküler ağırlığı ne kadar (bazların aksine, amioasitlerin moleküler ağırlığı büyük oranda değişiklik gösterir)? Bunun yanısıra, 3 boyutlu yapı bilgisine bu protein için ulaşabiliyor muyuz, ve bu 3 boyutlu yapıyı oluşturan fonksiyonel bölgeler/gruplar neler? Son olarak, bu proteinin hücre içerisindeki kontrolü amacıyla kullanılan translasyon sonrası değişiklikler [post-translational modifications] neler, ve ne anlam ifade ediyorlar?
Bu bölüme ilişkin gerçekleştirmenizi istediğim üçüncü ve son çalışma ise, CFTR geni için bu bölümde elde ettiğiniz bilgileri P53 ile kıyaslamanız. Bu iki gen bariz bir şekilde bu bilgiler açısından bir farklılık gösteriyor mu, ve bu farklılıkların nedeni ne olabilir? Hücre içi organizasyonda bu farklılıklar ne anlama geliyor olabilir?
Başarılar.
Ne öğrenmeyi bekliyoruz?
İlgilendiğimiz gene ilişkin genomik konum [lokasyon] bilgisine Genomic Views başlığı altında ulaşabiliriz. Bu bölümdeki en faydalı bilgi, genin kaç baz uzunluğunda olduğu. Diğer kritik bilgi ise, bu gene ilişkin alternatif bir konumun olup olmadığı. CFTR geni için başka bir bölge de rapor edilmiş, bunun birkaç sebebi olabilir.
Genomik veritabanları hakkında bilmemiz gereken en önemli şey, bu veritabanlarının sürekli değişken olduğu ve birden fazla kaynak tarafından üretildiğidir. İnsan Genom Projesi'nin ilk taslağının açıklandığı sıralarda DNA dizilimleme çalışmaları, iki farklı bireyin DNA'sı üzerinden devam ediyordu (biri James Watson). Bildiğimiz üzere insan genomu birçok delesyon [deletion] ile şekillenmiştir, bu durum da karşımıza, aynı gen için farklı genomik konumlar olarak ortaya çıkabilir. Genomik konum bilgisi bir referans noktasından itibaren hesaplanır, ancak aralardaki muhtemel delesyonların [deletion] veya deneysel hataların etkisi bu referans noktasından uzaklaştıkça artar ve karşımıza farklı genomik konum bilgileri çıkar. Buradan çıkarılması gereken en önemli ders şudur: herhangi bir çalışma yaparken, hangi veritabanındaki bilgileri kullandığımız, üzerinde çalıştığımız veritabanına ne zaman ulaştığımız ve bu veritabanındaki bilgilerin en son ne zaman güncellendiği hayati önem taşır ve bunların bir çalışmada mutlaka kayıt altında tutulması gereklidir.
Bu bölümde gerçekleştireceğiniz ilk çalışma, mevcut genomik bilgilerin elde edildiği veritabanının versiyon numarasını bulmak olacak. GeneCards'ın ham verilere farklı veritabanlarından ulaştığını unutmayalım (İpucu: genlere ilişkin konum bilgisi, GeneCards'ın GeneLoc bölümünde yer alıyor, aradığınız şey buralarda bir yerde).
GeneCards'taki bir sonraki başlık, Proteins. Proteinlerle ilgili aklımızda tutmamız gereken ilk şey, DNA dizilimindeki bilgilerin birebir karşılığı olmadığı. Ökaryotlarda genler ekzonlar şeklinde organize olmuştur ve her bir ekzonun arasında fonksiyonunu tam olarak anlayamadığımız ancak protein bilgisi kodlamayan intron adı verilen bölümler yer alır. Yani, GeneCards'tan elde ettiğimiz DNA diziliminin büyük kısmı protein bilgisi kodlamayan bazlardan oluşur. Bir diğer etkense, alternatif kırpılma [alternative splicing] olayıdır. Alternatif kırpılma, hücredeki şartlara göre bir geni oluşturan ekzonların tamamının değil de, her seferinde sadece belirli bir fonksiyonel kısmının proteine dönüşmesi durumudur. Yani, elinizdeki DNA dizilimine bakarak hücrede tam da bu dizilime uygun bir proteinle karşılaşamayabilirsiniz. Proteinlere ilişkin bahsedilmesi gereken son durum ise, proteinlerin 3 boyutlu dünyada var olduklarıdır. Çeşitli tarihsel nedenlerden ötürü DNA dizilimlerine uzun ve ince bir veriymiş gibi davranmayı severiz: böyle bir basitleştirme bazı kavramlara daha kolay hakim olmamızı sağlar. Ancak atladığımız nokta, gerçekte DNA'nın hücre içerisinde 3 boyutlu olarak yer aldığıdır. 3 boyutlu konum ve şekil bilgisi DNA'nın hangi bölgelerinin etkin olacağı başta olmak üzere birçok özelliğini etkiler, yine de mevcut bilimsel yaklaşımda bunların birçoğunu gözardı ederiz ve bu durum görünüş itibariyle bize çok da fazla bir zarar vermez (gerçekte, belki de açıklayamadığımız birçok mekanizmayı anlamamıza engel oluyor olabilir). Ancak konu protein olduğunda durum tamamen farklıdır: aminoasit dizilimi bilgisi göreceli olarak çok daha az faydalıdır ve bir proteine ilişkin söz söyleyebilmek için o proteinin (veya alternatif kırpılma sonucu ortaya çıkan başka bir şeklinin [variant]) 3 boyutlu yapısına ait bilgiye kesinlikle ihtiyacımız vardır.Bu bölümde gerçekleştireceğiniz ikinci çalışma tam da burada karşımıza çıkıyor. CFTR geninin kodladığı protein kaç aminoasit uzunluğunda, ve moleküler ağırlığı ne kadar (bazların aksine, amioasitlerin moleküler ağırlığı büyük oranda değişiklik gösterir)? Bunun yanısıra, 3 boyutlu yapı bilgisine bu protein için ulaşabiliyor muyuz, ve bu 3 boyutlu yapıyı oluşturan fonksiyonel bölgeler/gruplar neler? Son olarak, bu proteinin hücre içerisindeki kontrolü amacıyla kullanılan translasyon sonrası değişiklikler [post-translational modifications] neler, ve ne anlam ifade ediyorlar?
Bu bölüme ilişkin gerçekleştirmenizi istediğim üçüncü ve son çalışma ise, CFTR geni için bu bölümde elde ettiğiniz bilgileri P53 ile kıyaslamanız. Bu iki gen bariz bir şekilde bu bilgiler açısından bir farklılık gösteriyor mu, ve bu farklılıkların nedeni ne olabilir? Hücre içi organizasyonda bu farklılıklar ne anlama geliyor olabilir?
Başarılar.
Ne öğrenmeyi bekliyoruz?
- Bugün elde ettiğimiz verilere bir süre sonra tekrar erişmek istediğimizde farklılıklarla karşılaşabileceğimizi,
- Genomik ve proteomik bilginin arasında dünyalar kadar fark olduğunu ve tamamen farklı yaklaşımlar gerektirdiğini,
- Tek boyutlu veriyle (DNA dizilimi) çalışmanın 3 boyutlu veriyle (protein yapısı) çalışmaya kıyasla çok daha kolay ve yönetilebilir olduğunu, ve
- Farklı genlere ilişkin aynı tür bilgileri kıyaslamanın fonksiyonlara ilişkin birçok farklılığı açık bir şekilde ortaya koyduğunu.